Etiqueta: Problemas de Software
Internet
Hace unos minutos, un amigo me comentaba de lo difícil que estaba librarse de un virus, que en realidad es un ransomware llamado Anti Child Porn Spam Protection. Investigué …
Internet
Gmail tiene un límite de envío de correos electrónicos diarios además del tamaño de los archivos adjuntos (20MB) y el espacio de almacenamiento (7 GB y creciendo…). Si se …
Internet
Hay veces en la vida en que algún programador mete la pata. Y hay veces en que esas metidas de pata se prolongan en el tiempo. Muchas veces esos …
Internet
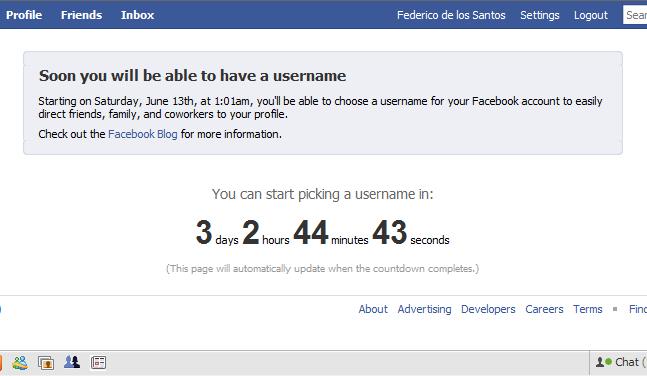
Dentro de 3 días y monedas (según la hora a la que escribo este post) Facebook habilitará la posibilidad de elegir un nombre de usuario, de forma que cada …
Internet
Desde que Facebook cambió su página inicial hace unos meses, ha crecido exponencialmente y yo mismo empecé a usarlo. Facebook ahora era menos para mandar y recibir abracitos de …
Internet
Muchos ríos de tinta se han escrito sobre los backups, los sistemas de recuperación de desastres y los de continuidad del negocios. Son todos relacionados, pero muy diferentes y …
Vida
Uno de los días más importantes e interesantes de mi vida profesional fue el 31 de diciembre de 1999. Al finalizar ese día, se produciría el cambio de milenio. …
Tecnología
Hace unos días, Windows Update me presentó una actualización del controlador de dispositivo (driver) para la tarjeta de red (NIC) de mi PC. Ésta es una Realtek RTL8168C. Mi …
Tecnología
Ayer Gustavo me decía en un mail: «te confirmo que el espacio en disco es un problema endémico de todas las empresas». Y eso creo que lo confirmamos día …
Uno de los grandes problemas de la virtualización, es que llegado cierto momento, algunos de los servidores que se quieren eliminar físicamente pueden ser demasiado complejos para migrar. Por …